Lecture 14 Query Planning & Optimization
Overview

这节课的任务就是讨论如何优化这个查询
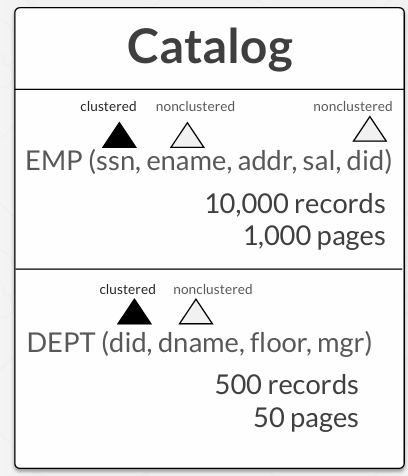
为了搭建查询优化的机制 要访问catalog
但我没记得这个东西之前讲过啊 可能因为我有一节觉得太难了没听
catalog(目录) -- 可以看做一个小型数据库 -- 有所有数据的元数据
比如在这个例子中 catalog表面有两张表 一张EMP员工表 一张DEPT部门表 还有数据量 和 page量
深色三角形 -- 在这个属性上建立了聚集索引
浅色三角形 -- 非聚集索引
聚集索引就是聚簇索引 聚集索引和非聚集索引 见Lecture 08 Tree Indexes
- 聚集索引: 决定了表中数据的物理存储顺序。一个表只能有一个聚集索引,因为数据记录的物理顺序只能按照一种方式排序。
非聚集索引: 非聚集索引不决定表中数据的物理存储顺序。它为数据创建了一个逻辑顺序,但实际数据存储位置不变。一个表可以有多个非聚集索引. 在索引树的叶子节点上存储的是指向实际数据行的指针(或行标识符),而不是数据本身。
说白了聚集索引就是真实page中存储的顺序 而非聚集索引就是给这个属性建了一个b+tree 然后叶子结点指向这个tuple在page中的真实位置
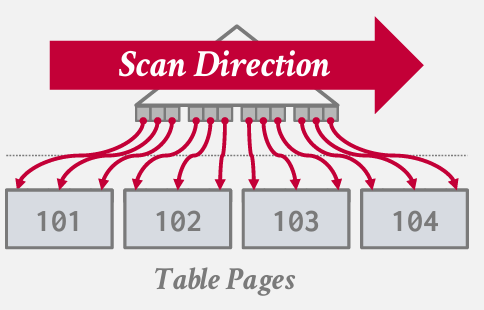
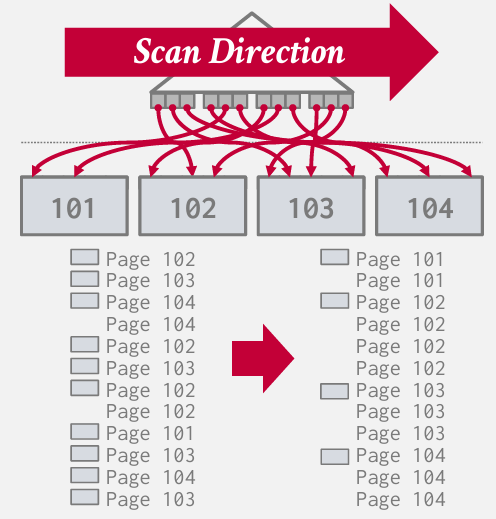
直接实现

笛卡尔积 -- 选择-- 选择 -- 投影
算成本
第一个operator: 笛卡尔积
50页DEPT 每一页都要逐页查看EMP 50 * 1000 = 5000 (笛卡尔积的成本)
输出成本: 原来我们在一页上容纳10条记录 (EMP中10,000条数据 1,000page; DEPT 500 records 50pages) 但是笛卡尔积使得大约每条记录扩宽了一倍 所以 5tuples一页 所以500 * 10,000 = 5,000,000 / 5 = 1,000,000page
或许仅考虑页数和记录数并不完美 -- 但是这只是预估 先不用管
第二个operator: 选择操作
读入上一个operator的输出: 1,000,000页
由于操作是EMP.did = DEPT.did -- 因为EMP中每一个tuple都能在DEPT找到对应的(多对多的关系) -- 所以其实选完就是EMP的条数 10,000 tuple 每5tuple 1page -- 所以2000page的写入
第三个operator: 选择操作
读入上一个operator: 2,000 pages -- 10,000 tuples
DEPT中的部门是不相同的 所以一个员工属于toy部门的概率为1/500(这只是平均情况)
所以输出是 10,000tuples/500 = 20 tuples / 5 =4 pages写入
第四个operator: 投影操作
4page 读取 1 page输出
total: 2,054,059的IO -- 2M I/Os
优化器的任务: 是否能优化
这里有一个优化
连接
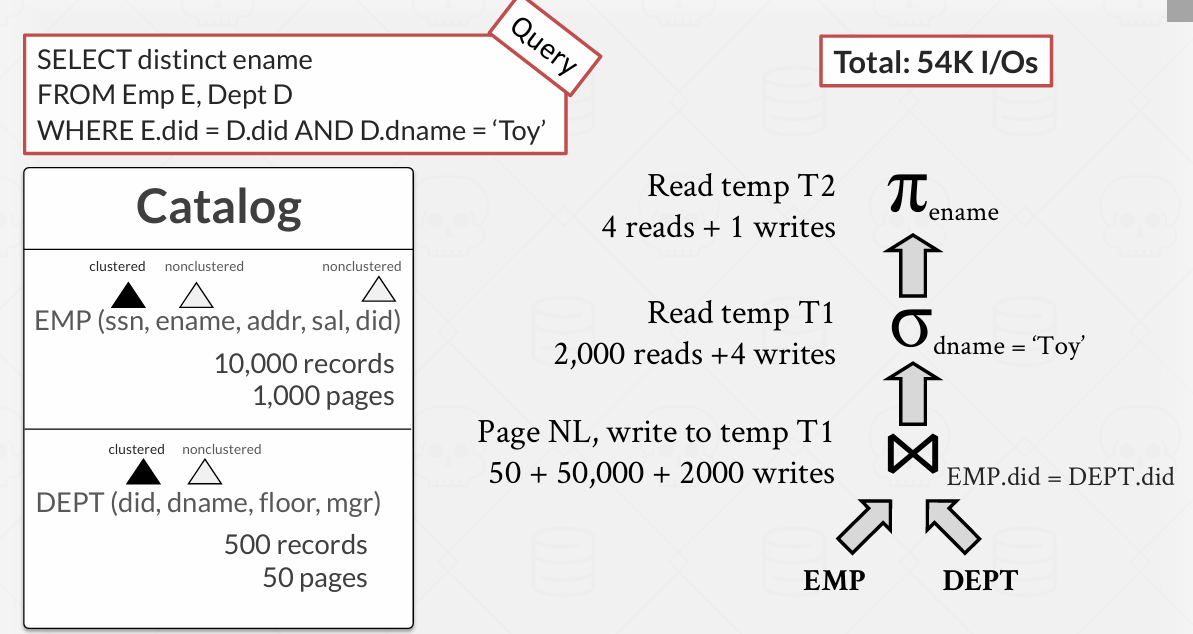
首次执行执行连接
哪种连接?
如果使用页嵌套循环法 -- 就是上图(直接生成了2000page的输入 只是将上一个方法中的下面两种操作符合并成了一种)
total: 54K IOs
由于存在非聚集索引 -- 所以 假设 Sort-merge join Lecture 11 Join Algorithms
算成本的时候跟buffer有关

假设我们需要50页缓冲池来执行归并排序
这里简化了 3M+3N = 31500 / 10 = 3150(这里的page可以放10个tuple 具体过程看Lecture 11 因为扫描的时候是在原page上扫描的)
最后依然是2000个生成
total: 7159IOs
如果采用流水线 所谓的流水线是避免中间结果物化到磁盘和内存中 -- 所以中间的write和read就擦除了 -- total: 3151 IOs
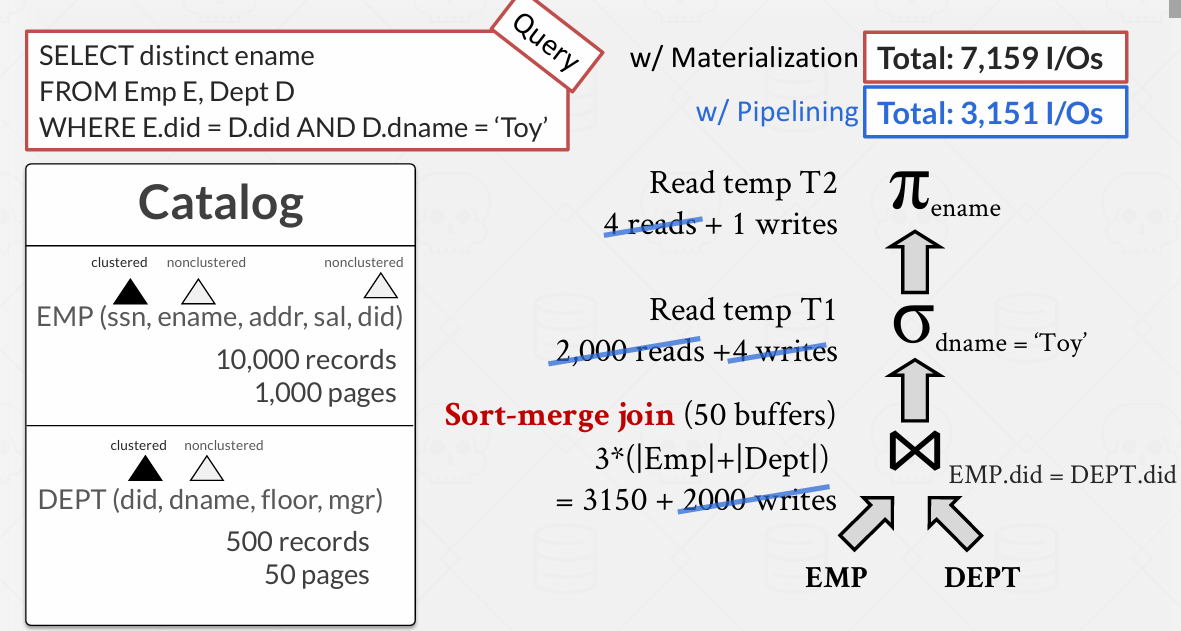
选择操作下推 -- 选择下推
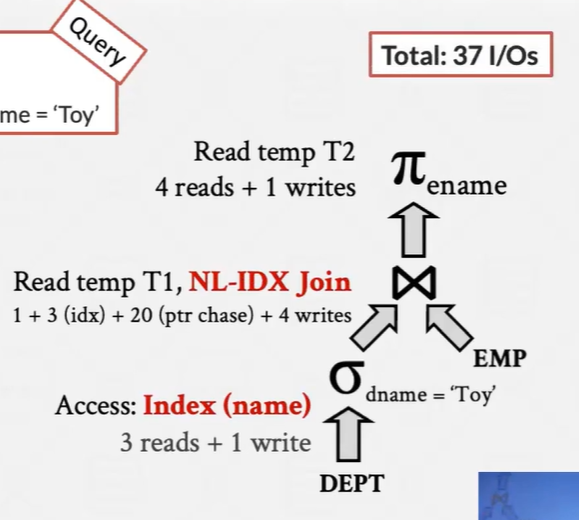
如果有一个索引 可以利用它 -- 假设第三次就从书中找到了 假设没有相同的部门且因为id为唯一的 -- 所有只有一条记录
然后执行一个索引嵌套循环连接Lecture 11 Join Algorithms
然后得到了一个更为简单的查询
Annotated RA Tree a.k.a. The Physical Plan
假设这就是我们要执行的计划
然后需要发送给调度器 但是问题是我们没法直接发送这个逻辑视图
还需要其他处理
红色的部分是一些标注 -- 比如说"首次筛选 查看部门表…… " -- 确定具体按那种方式查询
我们希望运行时系统执行的所有的细节都必须整合到一个数据结构中 该数据结构捕捉了查询树及其所有红色标注信息 然后这一结构发送至查询调度器
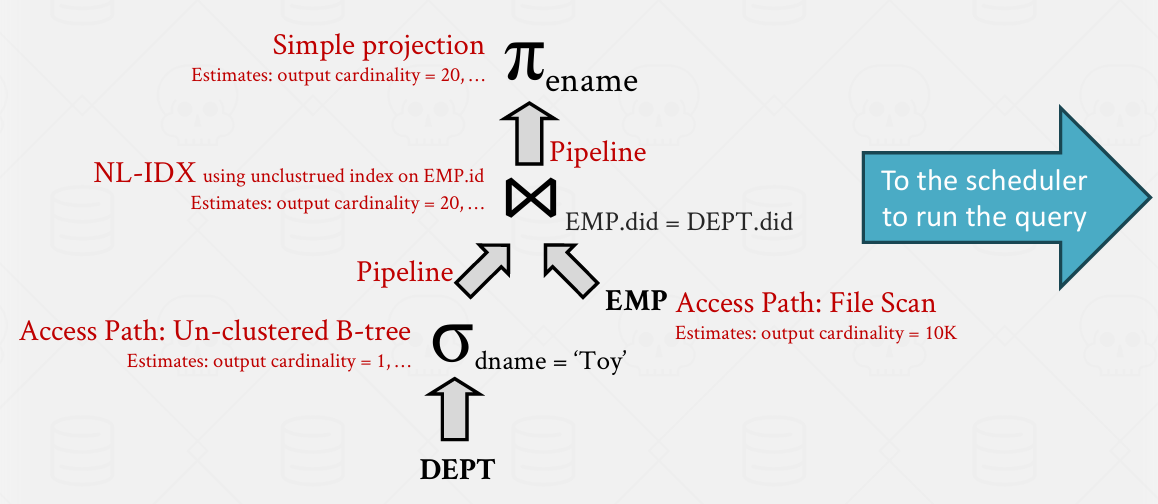
这里的思想是 逻辑计划评估成本 一旦找到合适的转化方案 就会转换成物理计划 然后发送给调度器
确定逻辑树是一个NP难问题 -- 我们可能不会去考虑可能得全空间
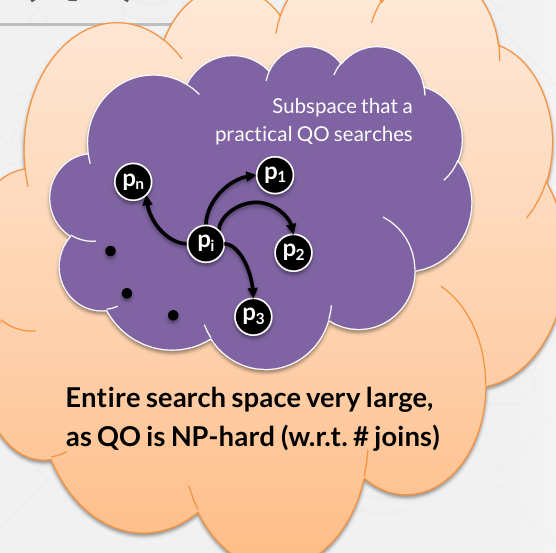
我们可能面对的是整个黄色云图的空间 我们需要设计优化器针对其中的一小部分进行搜索 所以问题就是我们怎么定义一个空间 使其成为能找到优质内容的空间
枚举可能通过rules完成 -- 后面会展示一些rules
eg. A join b = b join a
持续应用规则 每当应用一个安全的规则 都会得到一个新的计划 -- 然后只需要衡量新计划是否cheaper
另一个方法是 采取更智能的方式 以成本驱动的方式寻找组合
在实际的优化器中 会同时采用这两种方法
Rules
只需要应用规则即可 无需知道任何信息
Rules1: Predicate Pushdown: 谓词下推
大多数情况将选择操作下推是一个好主意 -- 经验法则
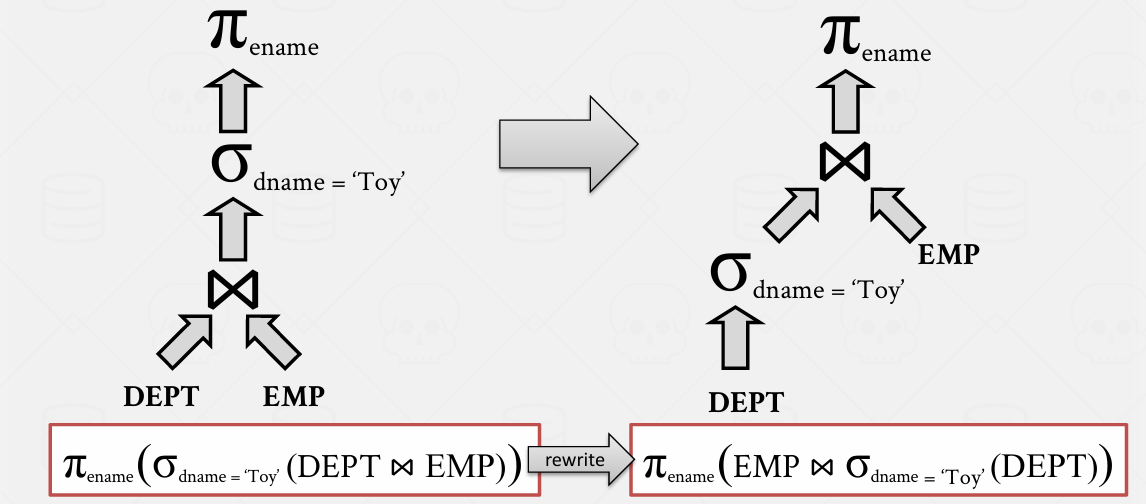
Rules2: Replace Cartesian Product
替换笛卡尔积
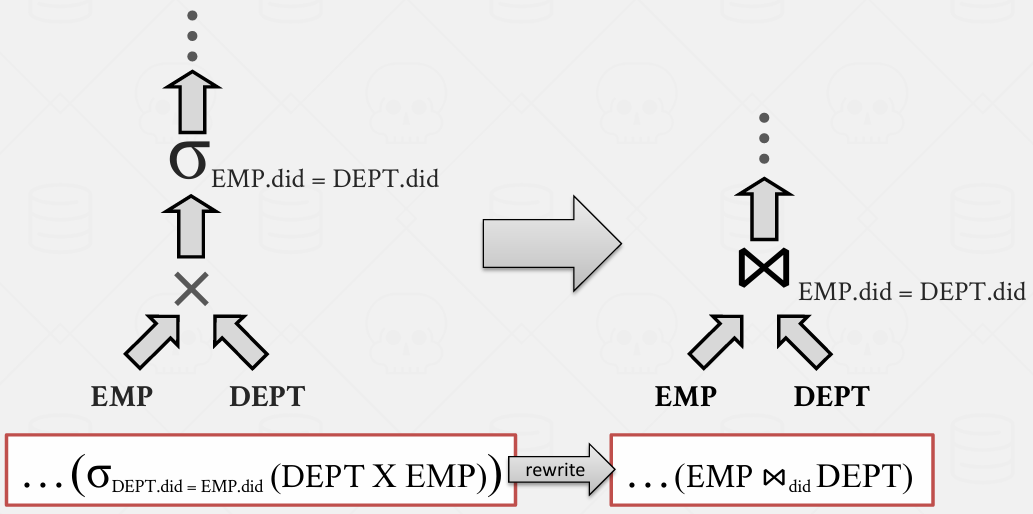
Rules3: Projection Pushdown
投影下推
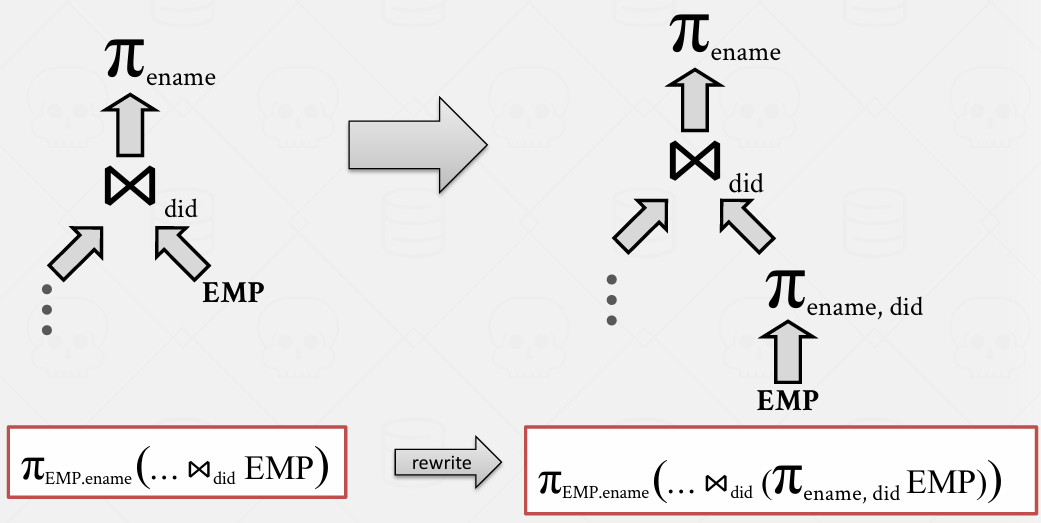

除此之外 有数百条规则
比如说图片中的有一个自然连接的交换 -- 换过来可能更好 -- 因为是谁作为外层循环的问题
Architecture Overview
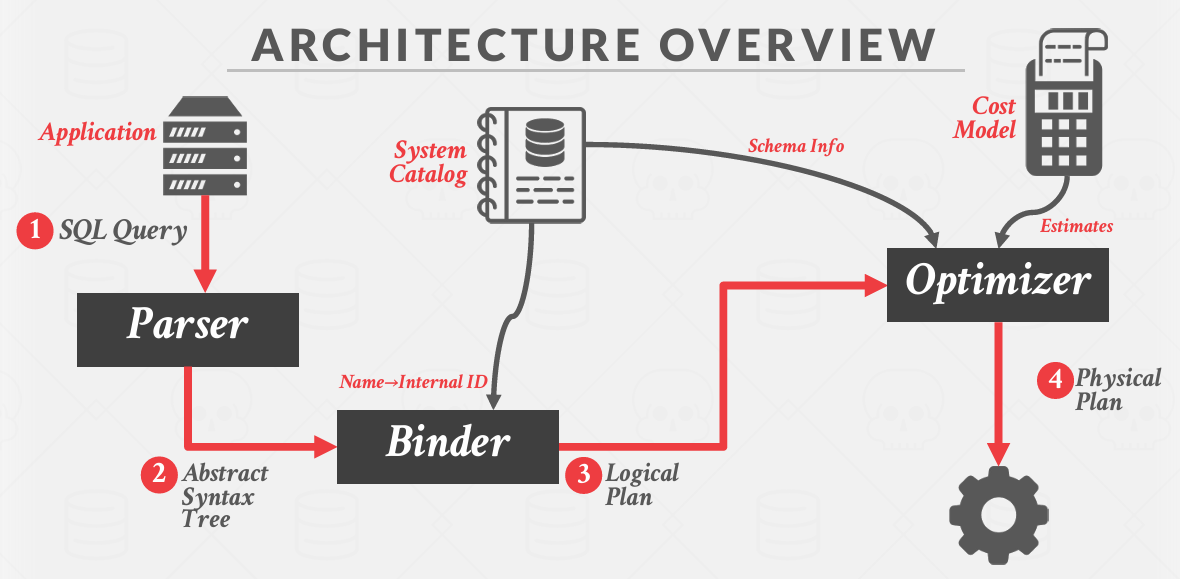
应用程序发送一个查询 给查询到达Parser(解析器) 解析器进行检查 生成抽象语法树
Binder(装订器)会去检查目录 确定这样做是否有意义
然后进入Optimizer(优化器) 在那里生成一个逻辑计划 优化器会对该逻辑计划进行审视 列出不同的重写方式 并确定其中最优的一种(利用了拥有的时间预算和从目录中获取的统计信息)
Cost Model是一些成本的方程式 无论如何 得到我们的面临的成本并最终生成一个物理执行计划(就是有注释的那张图)
Cost-based Query Optimization
让我们从某种风格的 QO 开始:基于成本的、自下而上的 QO(经典的 System-R 优化器方法)
Approach:
- Single relation.
- Multiple relation.
Nested sub-queries.
什么是表? 对于某个表如何访问它? 通过文件扫描 or 索引扫描 成本是多少?
首先确定何为单关系访问路径 然后通过连接操作不断合并这些路径 并利用结合律和交换律的性质进行优化 然后会讲嵌套子查询
然后会选择一种最佳计划 随着构建过程的推进 这是一种动态规划风格的方法
Single-Relation Query Planning
Pick the best access method:
- Sequential Scan
- Binary Search
Index Scan
这里的基本思路是 如果我通过文件扫描访问这个 通过索引访问那个 下一阶段 如果想要连接操作 那会是什么样的呢?(有点动态规划的意思了) 会采用我们在成本模型讨论中的简单启发式方法
System R Optimization
将查询分解为多个块并为每个块生成逻辑运算符
对于每个逻辑运算符,生成一组实现它的物理运算符。→联接算法和访问路径的所有组合
然后,以迭代方式构造一个“左深”连接树,以最大限度地减少执行计划的估计工作量
这里构造的是一个左深的连接树
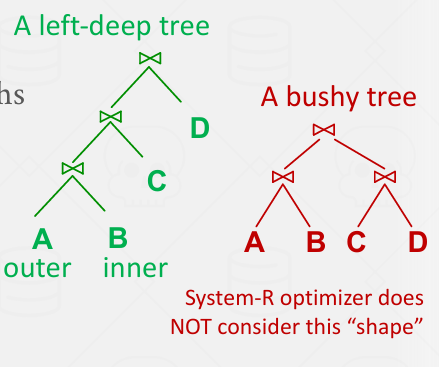
并没有考虑bushy tree 但其实有时候bushy tree的效果更好 但这其实这是一种选择
bushy tree属于紫色云图外部的部分

Step1: 找到对每个table最好的access paths
比如在这个例子中 假设 ARTIST和APPEARS使用顺序扫描 ALBUM使用索引查找
Setp2: 列举所有的join的方式
可能不会看笛卡尔积 与连接数乘级数增长
Step3: 确定成本最低的联接顺序
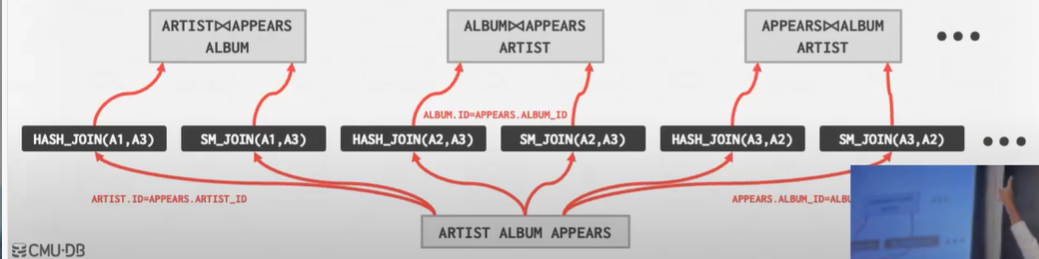
图片为了幻灯片简介 并没有全部列出所有情况
总之枚举了 先连接哪两个 用哈希连接还是归并排序连接
关键: 正在枚举探索结合律和交换律
然后我们整合这些内容 比如从成本效益的角度来审视这一问题 哈希可能更好
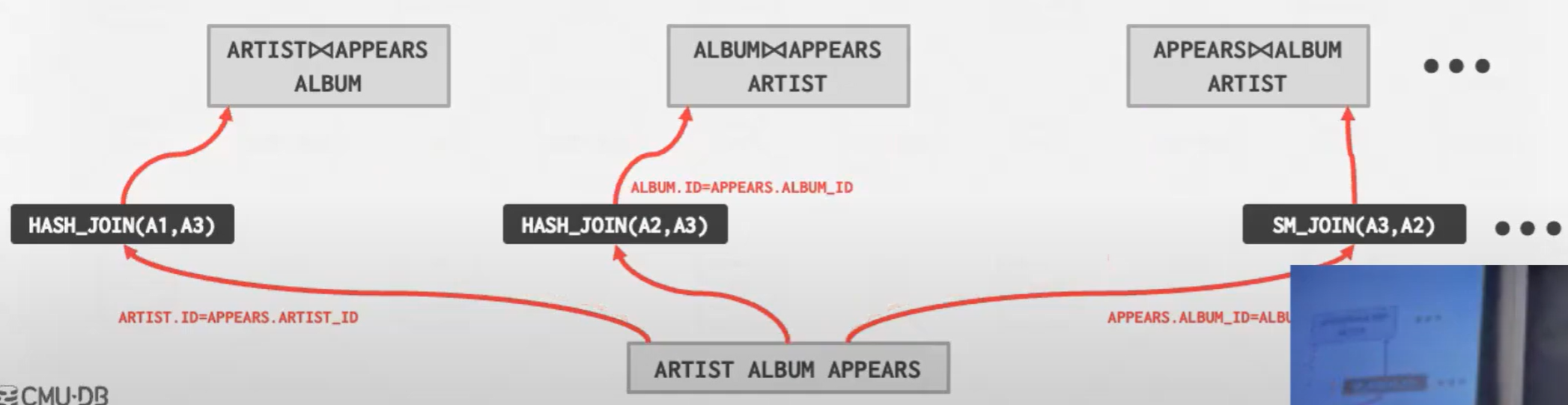
动态规划会自己决定选择cheaper的选择
然后递归
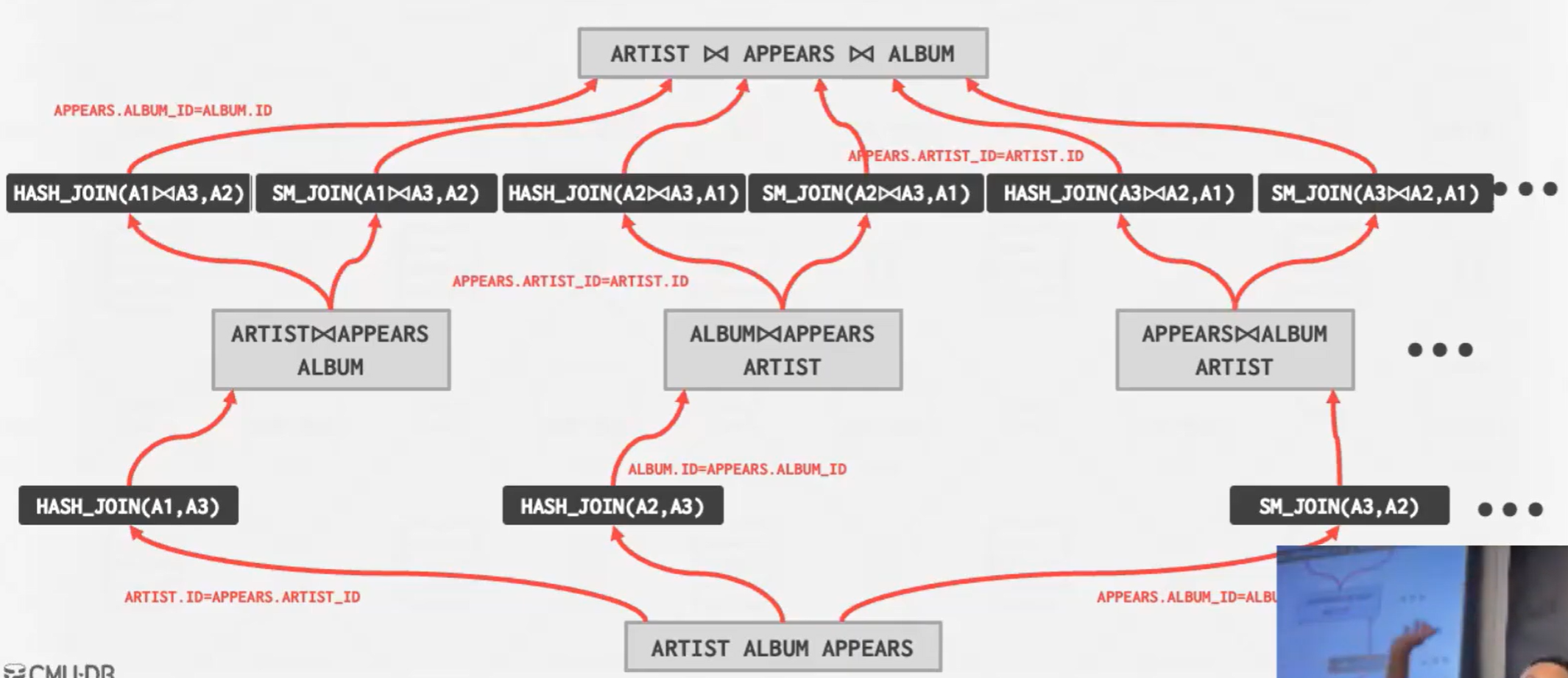
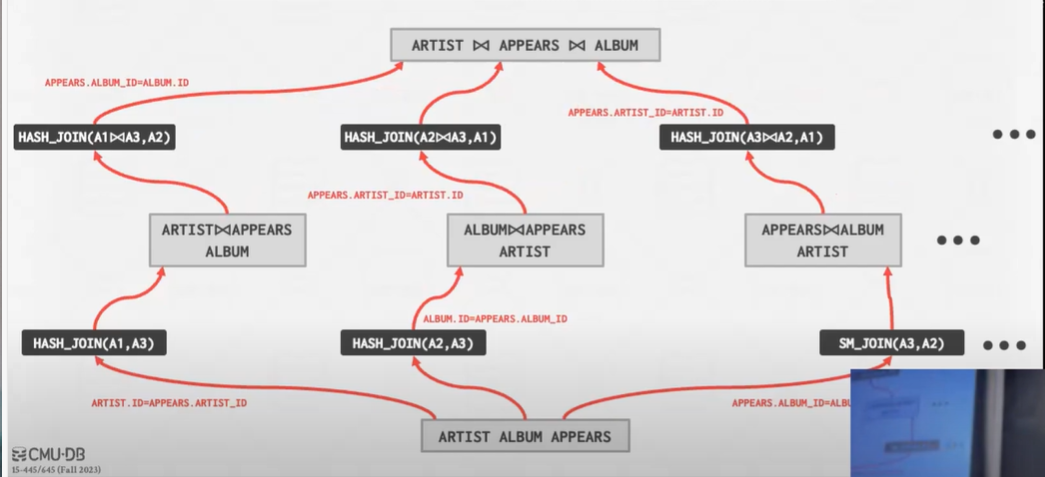
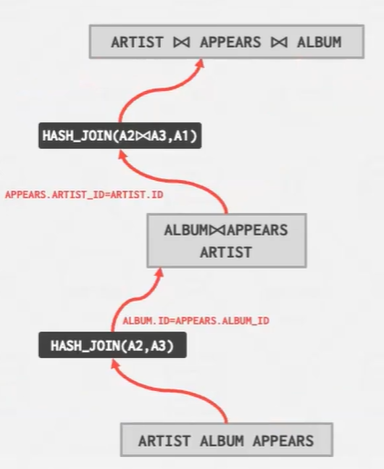
现在有三个计划幸存 再去找最优的那一个
尚未处理Order By
然后会在这个查询的基础上 最后实现一个 排序 -- 这是自底向上的方法
所有老系统都采用了这种方式 System R, DB2, MySQL, Postgres...
Multi-Relation Query Planning
Bottom-up Optimizaiton
上面提到的方法就是bottom-up Optimization的一个例子
Top-down Optimization
从我们希望查询的逻辑计划开始。通过将逻辑运算符转换为物理运算符来执行分支和定界搜索以遍历计划树
实际上我们发现有两种类型的规则需要应用
- 逻辑规则 比如谓词下推
- 与应用算法或考虑排序特性相关的物理规则
他会对每种操作进行成本操作 基于规则尝试 这些规则会分为两类 一类是逻辑到逻辑的转换 一种是逻辑到物理之间的转换
- 逻辑到逻辑的转换 就是之前讲的rules 比如 Join(a,b) to Join(b,a)
而逻辑到物理的转换 就是使用算法 比如 哈希连接 还是 归并排序连接
其实跟自顶向上选择的东西一样 也是选择算法 和 交换律那样子
example
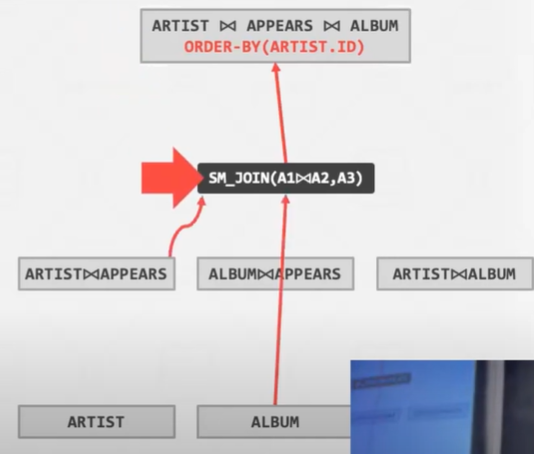
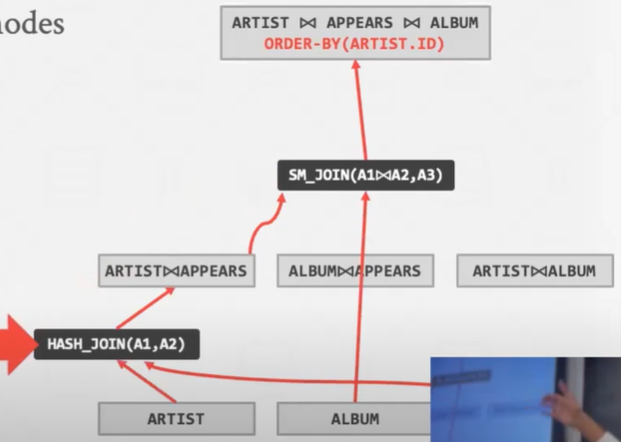
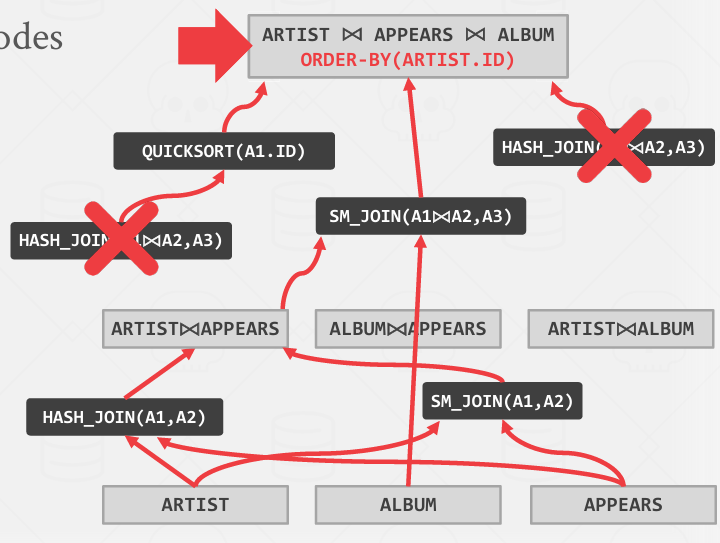
采用自顶向下的方法的好处在于 很快的就能得到一个正确的计划 属于从正确的东西不断进行改善
Nested Sub-Queries
前面提到的只适用于 单块查询 即 简单的 select from where而已
但是事实上会有复杂的嵌套子查询等等
当然我们可以先运行内层 再运行外层 但是更好地方法是尽可能重写查询 使其成为一个单块查询
所以这里的思路是与其并起来变成一个长条 不如展平 得到一个更大的快 给优化器一个全局试图 让他知道整个语句 知道优化什么
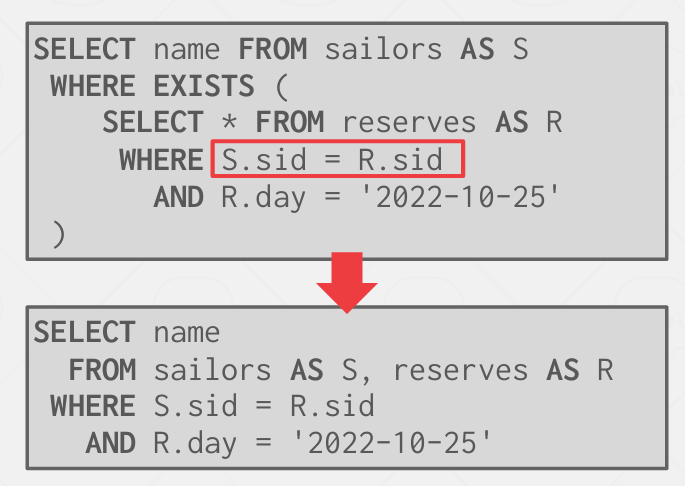
这里也会介绍一系列技术 用于展平 通常重写和分块是基于一系列规则的组件来完成的
但是并非都能展平 -- 15445就不深入了 可以选修高级数据库课程
也可以分解查询
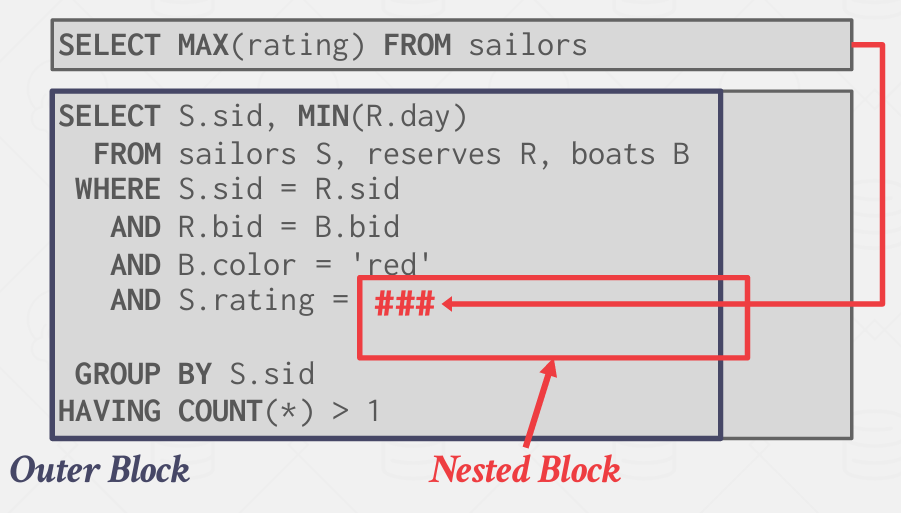
Cost Model
成本模型
结合一些内部陈本模型 -- 比较一个计划与另一个计划
成本模型通常包含两个组成部分
Physical Costs
我们的单位可能是 消耗多少个CPU周期, 消耗多少次IO输入输出, 需要一个恰当的模型
Logical Costs
取决于输出的大小 操作符的大小 以及我们所选定的算法
Statistics
预估执行查询的成本是通过在内部维护表相关信息来做的 DBMS 将有关表、属性和索引的内部统计信息存储在其内部目录中。不同的系统会在不同的时间更新它们
Selection Cardinality
选择基数
我们需要估计一个选择操作符的基数
比如说有一个谓词 age=9 但是我们不知道到底有多少数据满足这个条件
而且这个数量会影响到后续的规划
the selectivity(sel, 谓词选择性)是符合条件的元组的分数
若能在数据库中存储15个h值 并为每个值精确计数 sel = 4/45
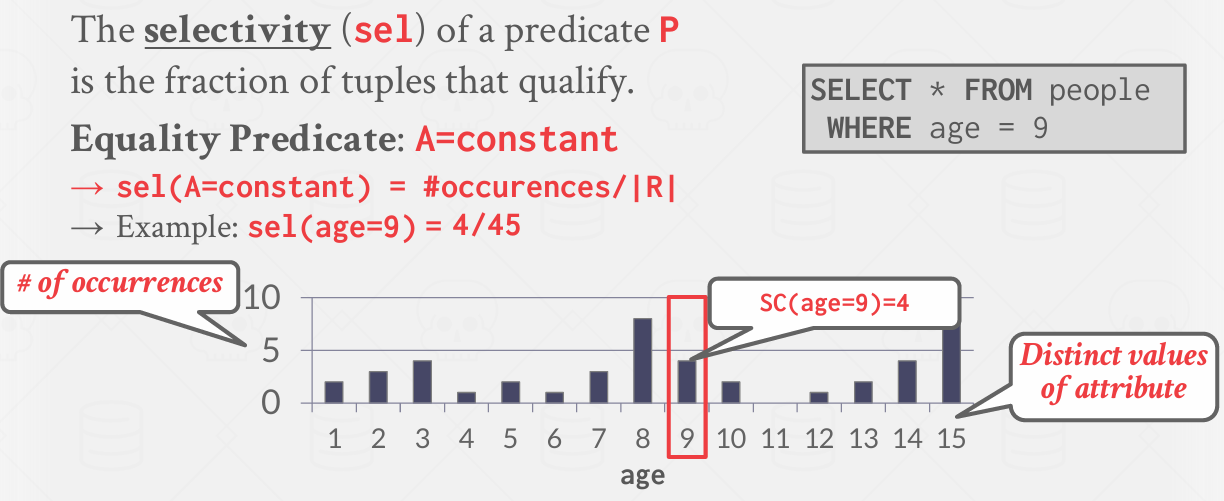
但这样做成本过高 因为存储详细值所需的空间可能与存储原始列所需的空间相同 因此可能会将数据库的规模翻倍 这并非明智之举
而且在这其中 还假设了独立性
如果两个谓词是独立的 我们可以直接结合起来 但情况并不总是这样
需要一些高级方法
Choice1: Histograms(直方图)
依然是呈现详细的信息 但是占的空间大幅减少
Equi-Width Histograms(等宽直方图): 分成桶 对每个桶存储总计数 大小相同 滑动计数
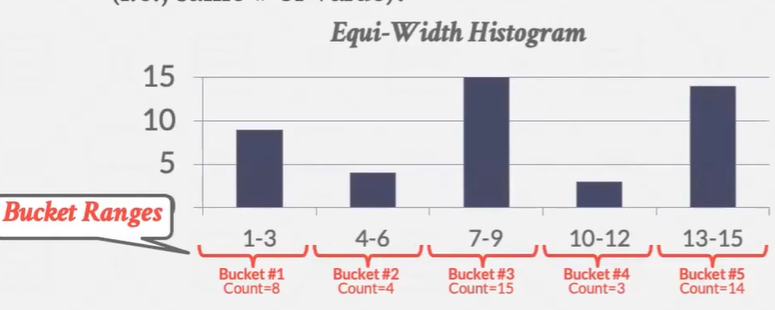
Equi-Depth Histograms(等深直方图) -- 桶的大小可以不同
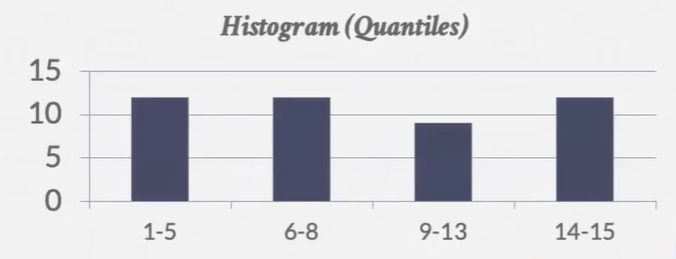
利弊会在高级课程里面讲解 -- 但使用直方图是为了减少空间 且 精确
Choice2: Sketches(草图)
也是类似统计方面的一种技巧 -- 详细信息会在高级数据库课程涉及
使用的关键算法叫HyperLogLog -- 是一种可以遍历估算出一个集合中不同值数量的算法
Choice3: Sampling(采样)
比如可以随机抽取百分之一的记录
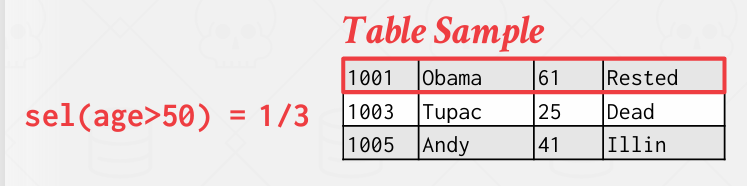
Conclusion
审视SQL查询 -> 逻辑计划 -> 物理计划(包含了所有细节 eg使用什么算法……) -> 调度器 表达式计算 重写->优化器 自顶向下/自底向上 动态规划构建得到最优解(NP难问题 只是局部最优)(在这里还讲了怎么预测个数)
Essential Query Optimization papers

如果想研究 可能要看5200个paper hhh
左边这篇论文是启动方式
左二 探讨的自顶向下
左三 开创了整个优化领域先河的系统性艺术
右一 混杂大量内连接和外连接